
導(dǎo)讀
在以ChatGPT為代表的人工智能受到社會(huì)廣泛關(guān)注的情況下,博物館的數(shù)字化建設(shè)需要適應(yīng)這一變化,從新技術(shù)的發(fā)展中獲益。博物館本身也應(yīng)該利用這一契機(jī),重新審視AI時(shí)代對博物館工作的要求,推進(jìn)自身的變革并探索博物館領(lǐng)域新的生長點(diǎn),重新規(guī)劃我們的工作方式和業(yè)務(wù)生態(tài)。
一、引言
ChatGPT自2022年11月30日橫空出世,很快吸引了社會(huì)各界的注意力,繼2016年的阿爾法圍棋(AlphaGo)擊敗圍棋世界冠軍李世石后,人工智能再次引發(fā)社會(huì)熱潮,成為一個(gè)街談巷議的話題?,F(xiàn)在,以ChatGPT為代表的人工智能技術(shù)在持續(xù)迭代中快速發(fā)展,并不斷地刷新人們的認(rèn)知。當(dāng)人工智能開始走向通用,被廣泛接受并融入社會(huì),它就可能會(huì)在各個(gè)領(lǐng)域發(fā)揮重要的作用,而作為主要公共文化機(jī)構(gòu)的博物館當(dāng)然也是其中的必要一環(huán)。從理論上說,人工智能在博物館中的作用似乎有無窮無盡的可能性,這也意味著它將成為智慧博物館建設(shè)的重要一部分。
二、ChatGPT、AIGC與人工智能
1、相關(guān)技術(shù)的概念
人工智能是計(jì)算機(jī)科學(xué)的一個(gè)分支,也是一個(gè)各學(xué)科融合的交叉學(xué)科。人工智能領(lǐng)域眾多,計(jì)算機(jī)視覺、機(jī)器學(xué)習(xí)、自然語言處理、機(jī)器人和語音識別向來被視為人工智能的五大重點(diǎn)領(lǐng)域或者說是核心技術(shù)。從自然語言處理和機(jī)器學(xué)習(xí)領(lǐng)域脫胎而成的AIGC,則被認(rèn)為有望引領(lǐng)內(nèi)容產(chǎn)業(yè)的新一輪生產(chǎn)力變革。AIGC狹義上來說就是利用AI自動(dòng)生成內(nèi)容的生產(chǎn)方式;廣義的AIGC可以看作是像人類一樣具備生成創(chuàng)造能力的AI技術(shù)。ChatGPT則只是AIGC的一個(gè)應(yīng)用而已,當(dāng)然ChatGPT本身也在迭代進(jìn)化當(dāng)中。
2、相關(guān)技術(shù)的演進(jìn)
當(dāng)約翰·麥卡錫等人在1956年8月底的達(dá)特茅斯之夏會(huì)議上提出并討論“人工智能”這一概念,大概沒能想到人工智能這條路會(huì)走得這么艱難,在前30多年幾乎默默無聞。當(dāng)然也沒想到60多年后的今天,人工智能技術(shù)會(huì)借著AIGC的東風(fēng)而這般如日中天,開始對社會(huì)造成如此巨大的影響。
從1956年“人工智能”概念首次被提出至今,人工智能大致經(jīng)歷了三次發(fā)展時(shí)期。第一次為初創(chuàng)期(1956—1974年)。該時(shí)期的任務(wù)是讓機(jī)器具備簡單的邏輯推理能力,也相繼取得了一批令人矚目的研究成果,如機(jī)器定理證明、跳棋程序等。第二次為成熟期(1975—1992年)。人工智能技術(shù)始終還是在波浪式發(fā)展,實(shí)用型的知識庫系統(tǒng)和知識工程成為80年代AI研究的主要方向,一些專家系統(tǒng)在醫(yī)療等領(lǐng)域取得成功。第三次為繁榮期(1993年至今)。這一時(shí)期,計(jì)算性能上的基礎(chǔ)性障礙已被逐漸克服。2006年,深度學(xué)習(xí)理論的突破更是直接帶動(dòng)了人工智能走向了一個(gè)嶄新的階段,互聯(lián)網(wǎng)、云計(jì)算、大數(shù)據(jù)等新興技術(shù)也為人工智能各項(xiàng)技術(shù)的發(fā)展提供了充足的數(shù)據(jù)支持和算力支撐。隨著AIGC的不斷發(fā)展,最近更是迎來了爆發(fā)式增長的新高潮。2014年,深度學(xué)習(xí)模型“生成式對抗網(wǎng)絡(luò)”(GAN)推出并迭代更新,2022年則成為AIGC的爆發(fā)之年,12月16日,美國《科學(xué)》雜志發(fā)布了2022年度科學(xué)十大突破,AIGC赫然在列。同樣是在2022年,從引爆AI作畫領(lǐng)域的DALL-E 2、Stable Diffusion等AI模型,到以ChatGPT為代表的接近人類水平的對話機(jī)器人,AIGC不斷刷爆網(wǎng)絡(luò),AI生成內(nèi)容種類豐富且效果逼真,其強(qiáng)大的內(nèi)容生成能力給人們帶來了巨大的震撼。
三、人工智能在博物館應(yīng)用的現(xiàn)狀
1、國外博物館的人工智能實(shí)踐
國外博物館比較早就注意并引入人工智能技術(shù),傳播服務(wù)領(lǐng)域是首先的受益者。2010年,谷歌公司在舊金山一家畫廊舉辦AI藝術(shù)展“深夢:神經(jīng)網(wǎng)絡(luò)藝術(shù)”,引發(fā)了藝術(shù)界關(guān)于AI創(chuàng)作的作品能否算作藝術(shù)品的熱烈爭論。2014年8月13日,英國泰特美術(shù)館進(jìn)行了為期5天的“夜幕”活動(dòng),通過網(wǎng)絡(luò)遠(yuǎn)程操控小機(jī)器人,足不出戶卻能身臨其境地參觀泰特美術(shù)館當(dāng)時(shí)正在展出的“英國藝術(shù)500年”展覽。2016年,泰特美術(shù)館又引入了意大利法布里卡團(tuán)隊(duì)研發(fā)的視覺識別程序,在掃描并學(xué)習(xí)了3萬多幅泰特美術(shù)館的藏品后,程序可以在路透社的新聞圖片庫與泰特美術(shù)館的作品圖片庫之間基于視覺和主題的相似性進(jìn)行對應(yīng)匹配識別(圖1),并將這些對應(yīng)成功的圖片在泰特美術(shù)館網(wǎng)站上建立一個(gè)不斷增長的虛擬畫廊。同年,挪威國家博物館與加州大學(xué)伯克利分校合作,采用神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)技術(shù),用來自于維基百科的文本資料對館藏的藏品圖像進(jìn)行識別訓(xùn)練,訓(xùn)練圖像依照相似度進(jìn)行聚類,并在此基礎(chǔ)上自動(dòng)形成按主題、顏色和風(fēng)格分類的展示(圖2)。

圖1 泰特美術(shù)館的圖片智能匹配

圖2 挪威國家博物館的藏品圖像聚類
2018年,紐約現(xiàn)代藝術(shù)博物館(MoMA)的數(shù)字媒體團(tuán)隊(duì)和Google藝術(shù)與文化實(shí)驗(yàn)室合作,開展通過機(jī)器學(xué)習(xí)和計(jì)算機(jī)視覺技術(shù)在舊展覽照片中識別每件藝術(shù)品的項(xiàng)目。團(tuán)隊(duì)使用算法來梳理30000多張舊展覽照片,并從中尋找與MoMA在線展示的65000多件作品相匹配的照片?,F(xiàn)在,我們在MoMA網(wǎng)站上,從一張1929年畫展上的照片打開一個(gè)鏈接,可以看到保羅·塞尚的標(biāo)志性作品(圖3)。2019年,西班牙達(dá)利美術(shù)館推出“達(dá)利活了”項(xiàng)目。博物館收集了6000張達(dá)利生前的影像,讓計(jì)算機(jī)花1000小時(shí)學(xué)習(xí)達(dá)利的臉部及身體動(dòng)作,以人工智能技術(shù)重現(xiàn)達(dá)利身影,創(chuàng)造了一個(gè)AI達(dá)利(圖4),并可以與觀眾進(jìn)行互動(dòng)。2019年另外一個(gè)主要的成果來自于美國大都會(huì)藝術(shù)博物館和微軟、麻省理工學(xué)院的合作項(xiàng)目。項(xiàng)目利用現(xiàn)在生成式對抗網(wǎng)絡(luò)從大都會(huì)藝術(shù)博物館的館藏中隨機(jī)選取藝術(shù)元素,然后把這些元素拿來通過GAN進(jìn)行訓(xùn)練,再通過算法推演組合隨機(jī)創(chuàng)建成一個(gè)藝術(shù)品,觀眾還可以在影像生成后自行調(diào)整每個(gè)藝術(shù)品“成分”的比重,給博物館的文創(chuàng)開辟了一條新路(圖5)。

圖3 紐約現(xiàn)代藝術(shù)博物館從舊展覽照片中識別藝術(shù)品

圖4 西班牙達(dá)利美術(shù)館“達(dá)利活了”項(xiàng)目的互動(dòng)裝置
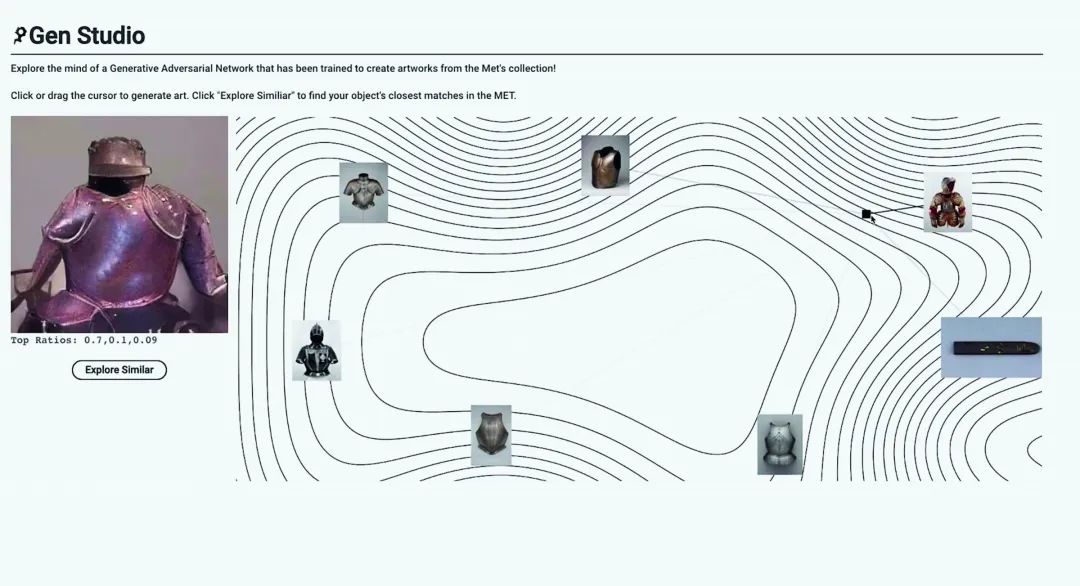
圖5 大都會(huì)藝術(shù)博物館利用GAN進(jìn)行新“藝術(shù)品”生成的演示圖
2、國內(nèi)博物館的人工智能實(shí)踐
與國外博物館相比,國內(nèi)博物館在人工智能應(yīng)用方面還不太重視,為數(shù)不多的一些應(yīng)用也往往流于表面。目前,相對較好的一些應(yīng)用大概是在文物修復(fù)方面。2017年,上海博物館在進(jìn)行“董其昌數(shù)字人文綜合展示系統(tǒng)”項(xiàng)目開發(fā)時(shí),引入人工智能技術(shù)。項(xiàng)目的作品欄目運(yùn)用卷積神經(jīng)網(wǎng)絡(luò)(CNN)等深度學(xué)習(xí)技術(shù)來分析明代繪畫作品中的一些基本元素,經(jīng)訓(xùn)練后,系統(tǒng)可自動(dòng)地完成畫面元素的識別和歸類,構(gòu)成素材數(shù)據(jù)抓取和聚類的自動(dòng)化模式(圖6)。在董其昌項(xiàng)目的基礎(chǔ)上,“‘宋徽宗和他的時(shí)代’數(shù)字人文專題”做了進(jìn)一步的探索。這一項(xiàng)目基于上海博物館繪畫藏品數(shù)據(jù)開展主題詞分析,研發(fā)書畫類文物專題知識圖譜。項(xiàng)目團(tuán)隊(duì)在董其昌項(xiàng)目所做的書畫藏品識別的基礎(chǔ)上,針對印章、題跋,以及擴(kuò)展至花鳥、人物等的繪畫元素,利用人工智能技術(shù)進(jìn)行信息提取。項(xiàng)目采用深度學(xué)習(xí)的方法,以卷積神經(jīng)網(wǎng)絡(luò)提取藏品圖像的特征,運(yùn)用監(jiān)督/無監(jiān)督方法學(xué)習(xí)特征分布到類別的映射,實(shí)現(xiàn)對繪畫元素的自動(dòng)識別、標(biāo)注,并構(gòu)建基于構(gòu)圖元素的繪畫內(nèi)容的索引,查詢比對與分析系統(tǒng),并通過K-means算法來實(shí)現(xiàn)圖像的聚類,以此輔助繪畫的研究和鑒賞工作(圖7)。
總之,博物館,尤其是國內(nèi)博物館,在人工智能的運(yùn)用上還顯得比較稚嫩,應(yīng)用場景也顯得單調(diào),但這也顯示出人工智能在博物館的運(yùn)用具有巨大空間。

圖6 董其昌作品畫面元素的識別和歸類

圖7 宋徽宗作品中的印章識別與聚類
四、影響人工智能在國內(nèi)博物館應(yīng)用的主要因素
1、缺乏創(chuàng)新性思維
國內(nèi)的博物館數(shù)字化或智慧化建設(shè)已經(jīng)開展了很長的一個(gè)時(shí)期,但很多博物館人還是沒有認(rèn)為它是一種必需品,仍然視之為錦上添花的附加品。這種觀念導(dǎo)致很多館不愿意為數(shù)字化工作去開動(dòng)腦筋、花大力氣,其結(jié)果就是國內(nèi)的博物館數(shù)字化建設(shè)始終在原有的數(shù)據(jù)采集、藏品管理及服務(wù)導(dǎo)覽等有限的范圍之內(nèi)兜圈子,建設(shè)項(xiàng)目的同質(zhì)性問題始終無法解決。所以,要沖破目前的數(shù)字化建設(shè)的瓶頸,就必須自上而下擺脫習(xí)慣性思維,就必須提倡創(chuàng)新性思維。
我們必須體認(rèn)和接納數(shù)字化帶來的新工作模式和工作方法,在破與立之中重建新的平衡,在多學(xué)科的參與下協(xié)同創(chuàng)新,發(fā)展出屬于其自身的新的成長空間。也只有在這樣的基礎(chǔ)上,代表新生產(chǎn)力的人工智能技術(shù)才可能順利地接軌博物館的業(yè)務(wù)工作。
2、封閉式的業(yè)務(wù)模式
在人文類博物館,單打獨(dú)斗的個(gè)體研究也還是一種常態(tài),學(xué)術(shù)孤島現(xiàn)象普遍存在。而且由于研究人員來源學(xué)科的單一,而博物館實(shí)際研究學(xué)科又有細(xì)分化趨勢,使得研究方式的細(xì)微精深成為博物館研究的常態(tài)。這與目前多學(xué)科融合研究的趨勢背道而馳,更是與當(dāng)前數(shù)字技術(shù)背景下的知識生產(chǎn)方式格格不入。
此外,ChatGPT之所以能夠成功,海量的數(shù)據(jù)訓(xùn)練功不可沒,這就要求有一個(gè)開放性的數(shù)據(jù)環(huán)境。在國內(nèi),智慧博物館建設(shè)開展以來,各館都在做藏品數(shù)據(jù)的采集,僅全國移動(dòng)文物普查中,統(tǒng)一標(biāo)準(zhǔn)登錄文物完整信息的國有可移動(dòng)文物就有2661萬件/套,登錄文物照片達(dá)5000萬張,數(shù)據(jù)總量超過140TB,這也是智慧博物館建設(shè)最大的基礎(chǔ)性成果。但事實(shí)上,業(yè)外人士依然望資源而不可得。造成這一狀況的原因并不在技術(shù)和資源本身,而是在博物館人的固有思維上。要解決這一問題,需要博物館人員,尤其是管理者建立開放性思維并轉(zhuǎn)變封閉式的業(yè)務(wù)模式。人工智能時(shí)代的到來,正是一個(gè)契機(jī),是打開博物館資源封閉大門的一把鑰匙。
3、數(shù)據(jù)基礎(chǔ)薄弱
人工智能,數(shù)據(jù)是基礎(chǔ)。博物館當(dāng)前的數(shù)據(jù)資源,從量上來看確實(shí)不少,但在質(zhì)的方面就很難恭維,甚至可以用薄弱來形容。這個(gè)弱首先體現(xiàn)在由于采集標(biāo)準(zhǔn)不統(tǒng)一,以及各館之間的人力和財(cái)力的不平衡,造成各館的數(shù)據(jù)采集質(zhì)量差別很大,特別是大館和中小館之間,差距顯而易見。如果這一弱點(diǎn)通過投入還可以盡快彌補(bǔ),如數(shù)字化項(xiàng)目中添置硬件設(shè)備,那么在不易察覺的軟的一塊,其薄弱則更讓人擔(dān)心。
我們需要多加努力,盡快建立起博物館自己的數(shù)字資源建設(shè)標(biāo)準(zhǔn)規(guī)范,也要建立對網(wǎng)上資源進(jìn)行搜集、篩選、編目、加工、使用的方法和相應(yīng)的技術(shù)標(biāo)準(zhǔn)規(guī)范,還要建立開放的、可互操作的數(shù)字資源組織與管理標(biāo)準(zhǔn)規(guī)范,以及建立可互操作的數(shù)字對象調(diào)度機(jī)制等。在統(tǒng)一標(biāo)準(zhǔn)下形成良好的數(shù)據(jù)集和語料庫,為人工智能的訓(xùn)練和學(xué)習(xí)提供優(yōu)質(zhì)的數(shù)據(jù)基礎(chǔ)。
五、博物館數(shù)字化建設(shè)中人工智能應(yīng)用的考量
1、重視人工智能技術(shù)在博物館的應(yīng)用
面對人工智能技術(shù)的飛速發(fā)展,博物館持何種態(tài)度,決定了它會(huì)如何作為。博物館管理者應(yīng)當(dāng)正確理解當(dāng)前人工智能技術(shù)飛速發(fā)展的本質(zhì),充分認(rèn)識到人工智能時(shí)代所帶來的機(jī)遇和對博物館工作的推動(dòng),努力發(fā)揮自身數(shù)據(jù)資源獨(dú)特而豐富的優(yōu)勢,有效利用自身專業(yè)所長順勢而為,抓住機(jī)遇主動(dòng)融入當(dāng)前由人工智能技術(shù)引發(fā)的社會(huì)發(fā)展。我們需要順應(yīng)人工智能的潮流,在貢獻(xiàn)屬于博物館領(lǐng)域的智慧和解決方案的同時(shí),推進(jìn)博物館的變革并探索博物館領(lǐng)域新的生長點(diǎn),重新審視AI時(shí)代對博物館工作的要求,重新定位博物館的核心能力,重新規(guī)劃博物館的工作方式和業(yè)務(wù)生態(tài)。
2、把握人工智能在博物館的主要應(yīng)用場景
在博物館服務(wù)領(lǐng)域,類似ChatGPT的智能問答將大行其道,不僅能夠取代近幾年以程序生成的機(jī)器問答,也足以代替人工型的知識問答。博物館的導(dǎo)覽程序也可以通過接入人工智能技術(shù)而使觀眾獲得如自助查詢、智能推薦等更便捷和全面的體驗(yàn)。
在研究領(lǐng)域,“人文學(xué)科,研究人類社會(huì)和文化各方面的學(xué)術(shù)學(xué)科(如歷史、語言學(xué)、政治、神學(xué)和文學(xué)),面臨著數(shù)字工具和方法所帶來的機(jī)遇,這些工具和方法可以促成變革性的創(chuàng)新研究”。在研究工作中,除了能夠提高資料檢索效率以及當(dāng)作寫作助手以外,AIGC對不同來源的研究資源的不斷補(bǔ)充和對使用對象的一視同仁會(huì)進(jìn)一步模糊了行業(yè)之間的界限區(qū)分,有助于打破學(xué)科界限,有利于跨學(xué)科合作研究的形成。此外,在博物館藏品及其相關(guān)數(shù)字資源累積了龐大的資源和能量以后,可以在保持原有研究特點(diǎn)和優(yōu)勢的前提下,去嘗試進(jìn)行以數(shù)字資源為主要對象的數(shù)字化研究工作。在最近進(jìn)行的上海博物館民國紙幣研究系統(tǒng)的開發(fā)中,我們就通過AI技術(shù),采集獲取紙幣上各種信息,并進(jìn)行匯聚、比照,獲得深入研究所需要的信息源(圖8)。通過調(diào)用數(shù)據(jù)集進(jìn)行各類特征的自動(dòng)排列和比對,有利于博物館民國紙幣研究工作的開展和相關(guān)知識圖譜的構(gòu)建。
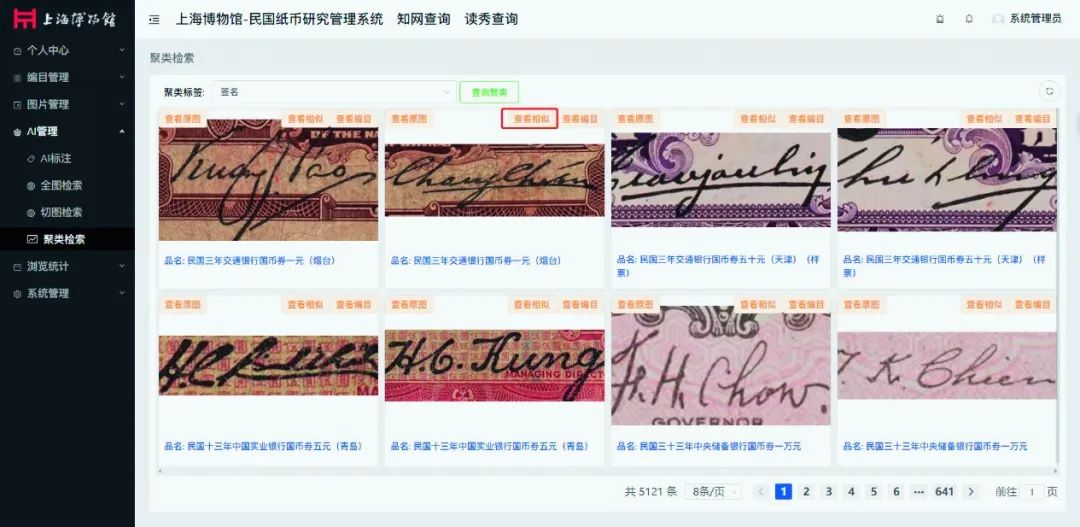
圖8 民國紙幣研究系統(tǒng)中的紙幣簽名識別和聚類
在展覽展示領(lǐng)域,既可以在策展過程中利用AIGC工具,按描述從數(shù)據(jù)庫中自動(dòng)將關(guān)聯(lián)數(shù)據(jù)生成不同主題并進(jìn)行推送,以此形成簡單的策展文案和展品目錄,提高策展的效率和水平;也可以利用機(jī)器學(xué)習(xí)算法對目標(biāo)觀眾的喜好和興趣進(jìn)行預(yù)測和分析,更加精確地設(shè)計(jì)展覽內(nèi)容和展品,提高展覽的吸引力和參觀體驗(yàn);可以利用AIGC工具高效生產(chǎn)圖像、視頻、3D模型等,并結(jié)合已有的文本和數(shù)據(jù)直接生產(chǎn)出更加智能化和更富有敘事性的可視化產(chǎn)品。
3、理性對待人工智能應(yīng)用的利弊
博物館的人工智能應(yīng)用還是要以博物館的宗旨為依歸,以博物館的業(yè)務(wù)需要和業(yè)務(wù)發(fā)展為中心,既要從實(shí)際出發(fā),循序漸進(jìn),不盲目沖動(dòng),不為技術(shù)所綁架,又要抓住機(jī)會(huì),促使新興技術(shù)成為推動(dòng)博物館轉(zhuǎn)型升級的引擎,也要警惕并防止脫序而產(chǎn)生災(zāi)難性的后果。
六、結(jié) 語
在新技術(shù)革命浪潮席卷全球之際,博物館需要勇敢面對,順勢而為。雖然ChatGPT等人工智能技術(shù)在目前來看還并非十全十美,甚至在某些方面還存有一定風(fēng)險(xiǎn),但其在問題理解、人機(jī)交互方面的強(qiáng)大,以及由此帶來的內(nèi)容生成方面的潛力是不容忽視的。未來已來,博物館要充分借助數(shù)據(jù)資源優(yōu)勢,融合人工智能等新型技術(shù),為更好地實(shí)現(xiàn)博物館的數(shù)字化轉(zhuǎn)型和創(chuàng)新發(fā)展服務(wù)。





